Why EEVEE
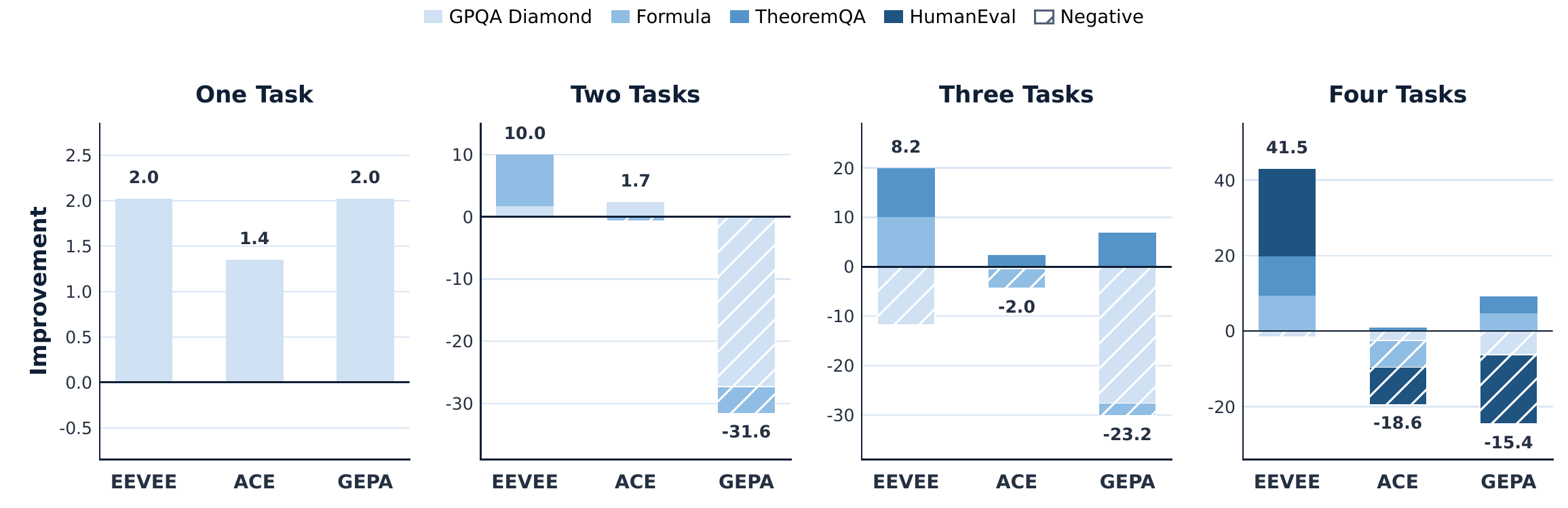
One learned prompt breaks down as task mixtures grow.
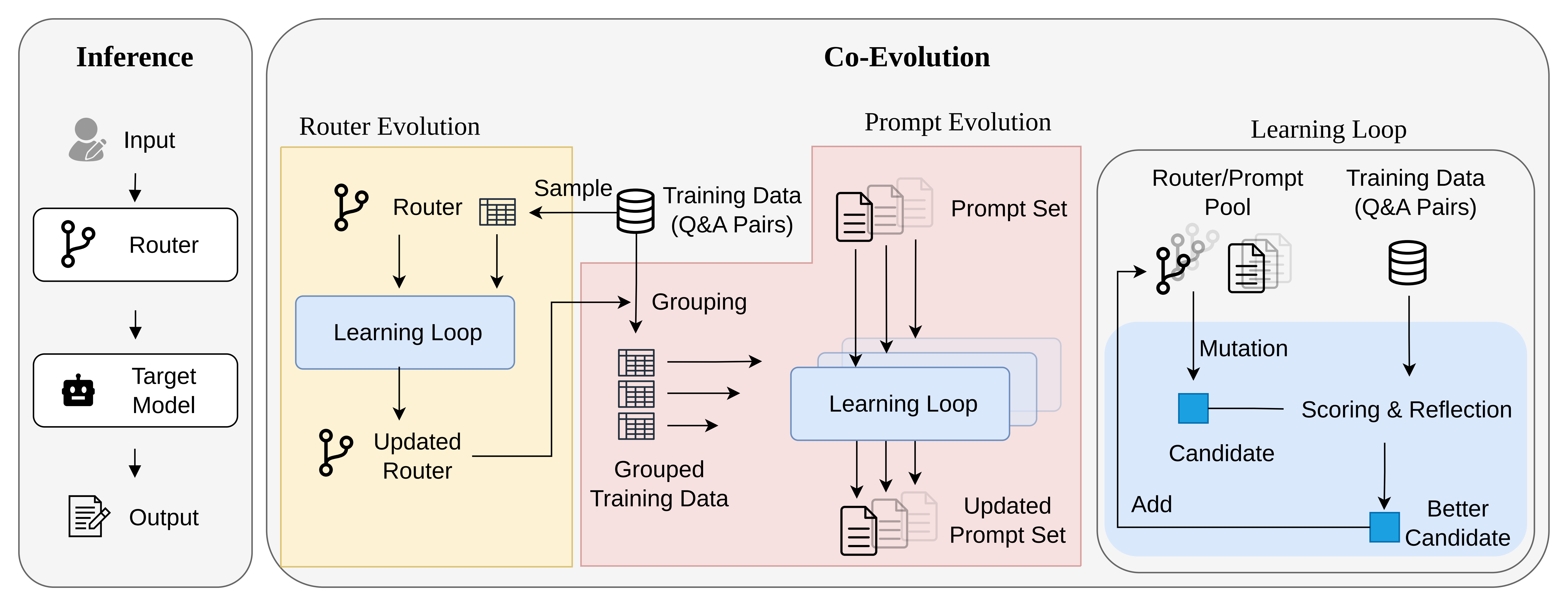
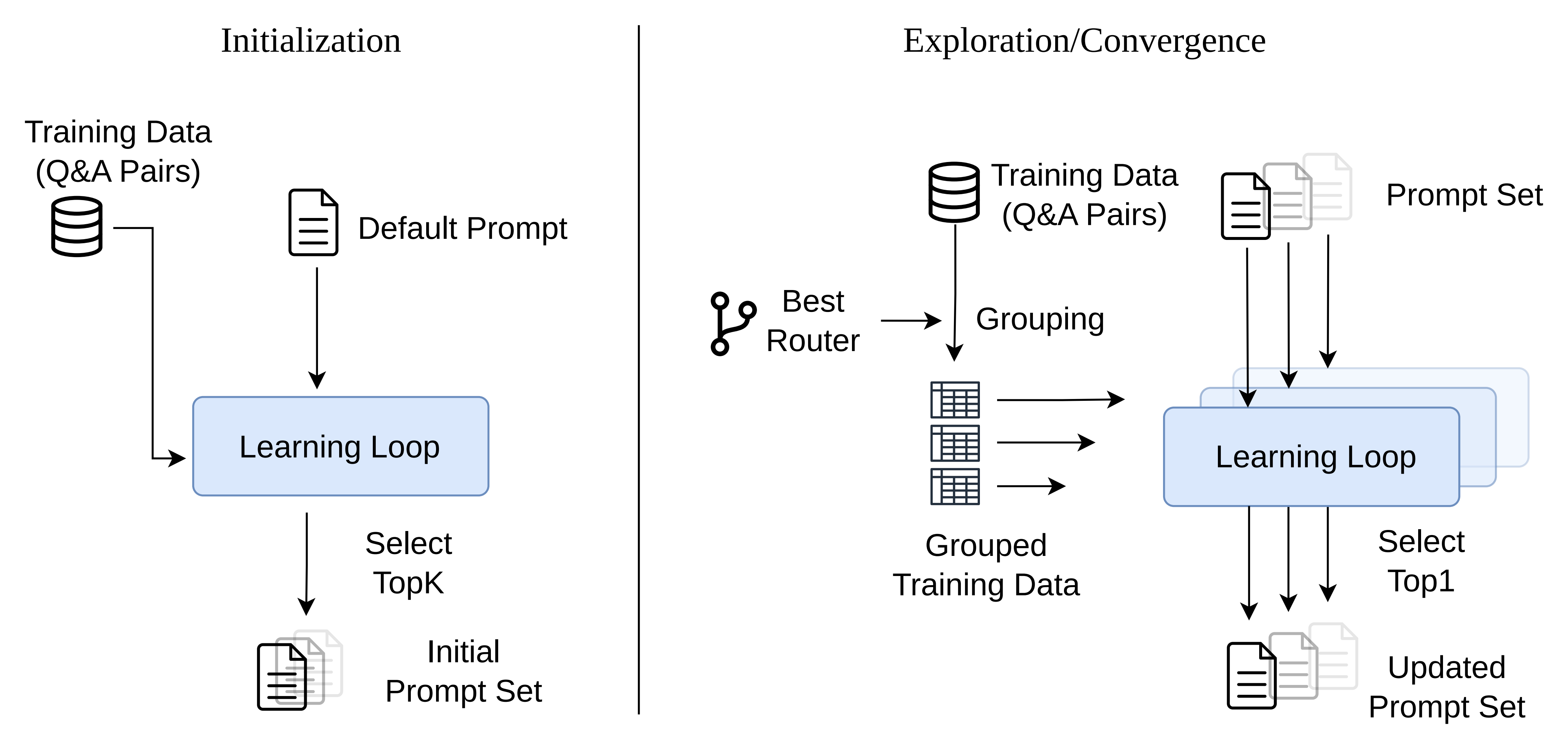
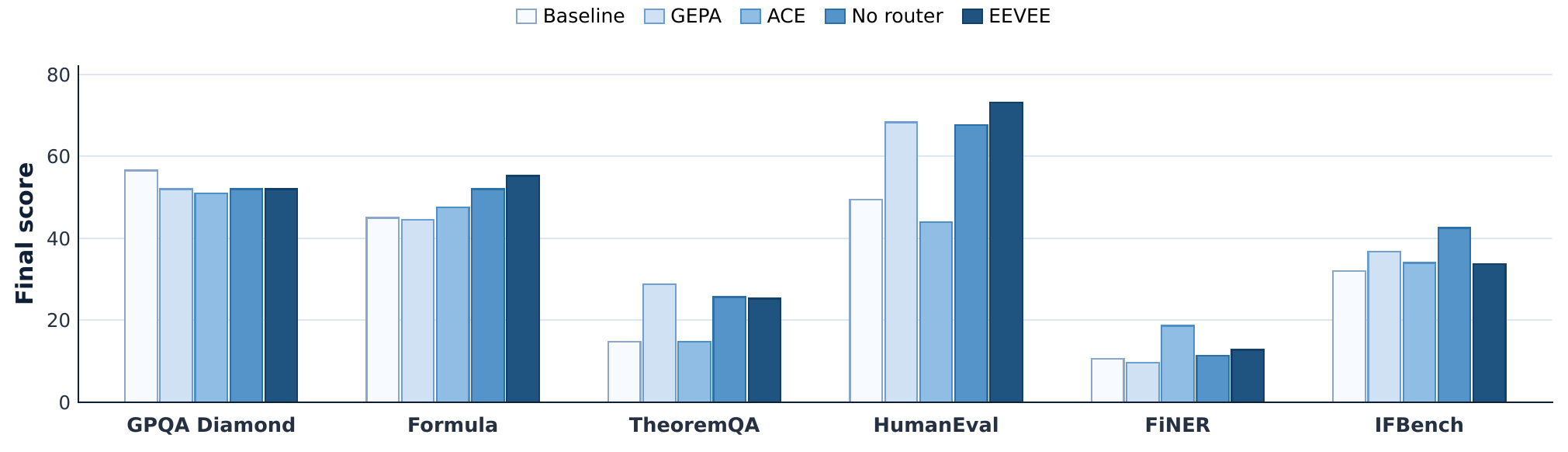
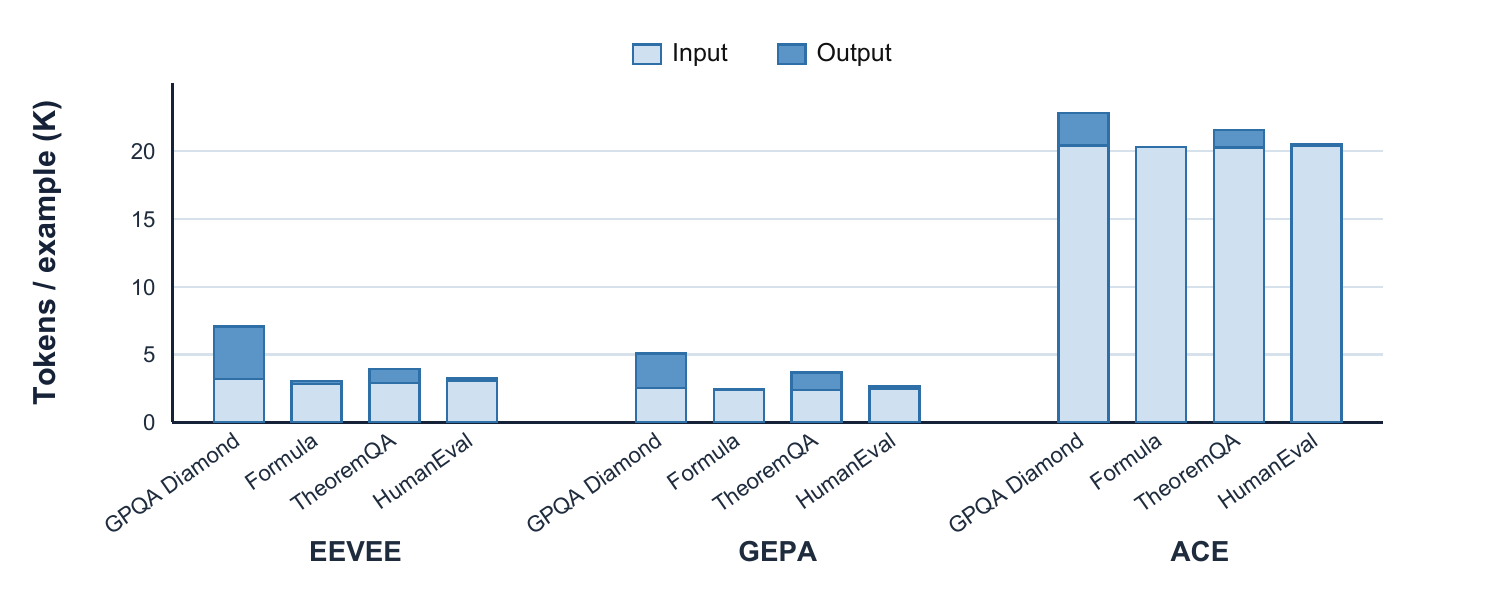
Prior test-time prompt learning methods are strongest when the feedback stream comes from one benchmark. Real agents are different: they see knowledge QA, symbolic reasoning, financial formulas, and code generation in the same operating loop.
In the paper's incremental setting, GEPA and ACE accumulate negative retention as more benchmarks enter the stream. EEVEE stays positive because the router separates incompatible feedback before each prompt specializes.